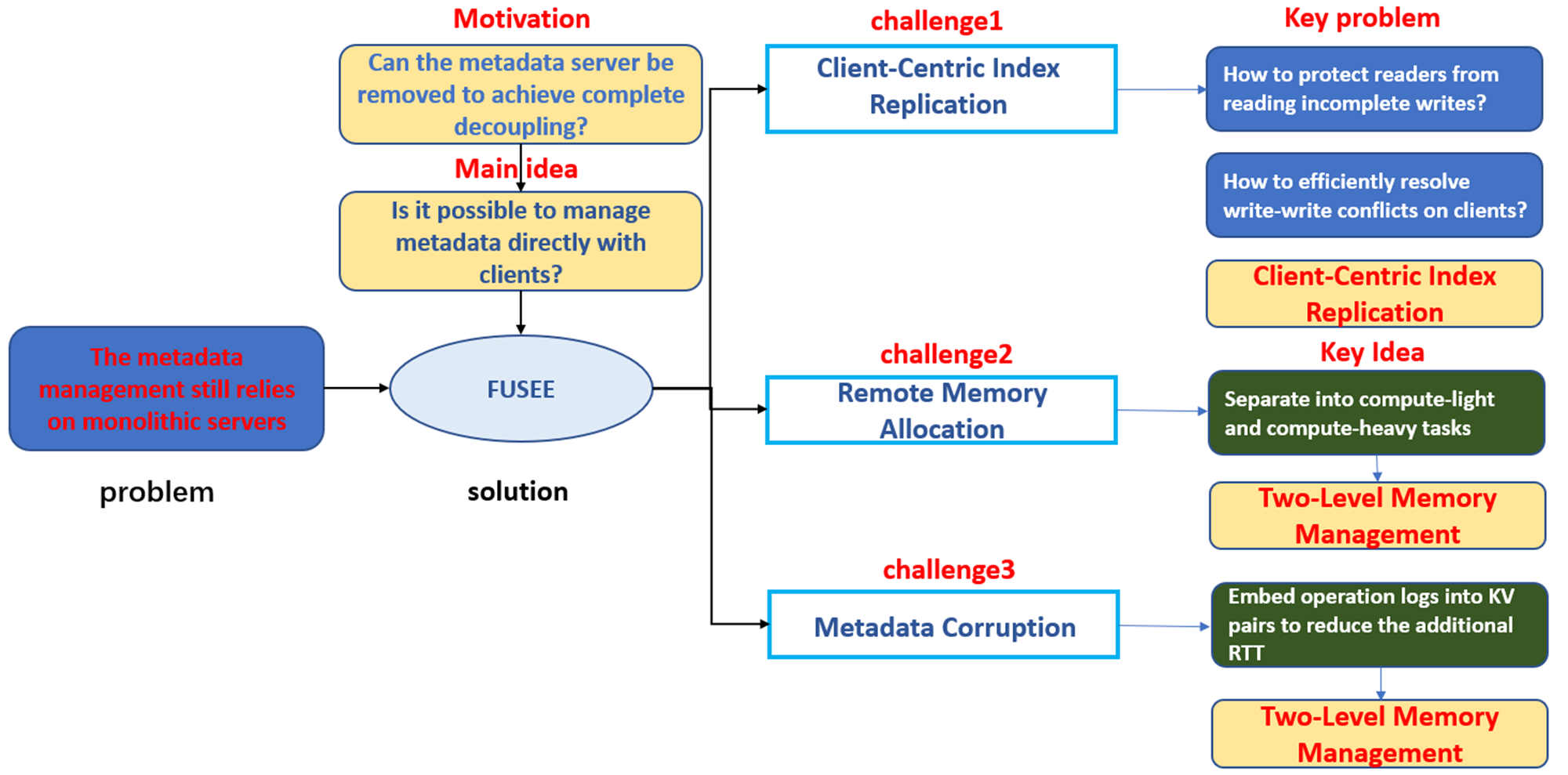
FUSEE: A Fully Memory-Disaggregated Key-Value Store 论文阅读笔记
FUSEE: A Fully Memory-Disaggregated Key-Value Store阅读笔记
今天给大家带来的是今年fast23的一篇paper,FUSEE: A Fully Memory-Disaggregated Key-Value Store,一种完全解耦的K-V存储架构。
Background
In-Memory Key-Value Stores
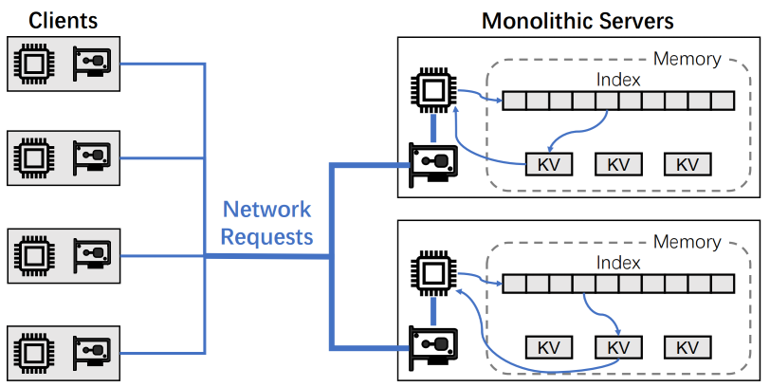
现在有很多著名的K-V Store,著名的例如redis,还有亚马逊的clashcache等等,传统的K-Vstore的工作模式,是用户从客户端发送网络请求到单体的存储服务器上,由服务器上的CPU进行K-V操作(insert、search、delete、update)来实现对K-V pair的使用。
但是由于传统K-V store中,采用了单体服务器的这样一个模式,导致cpu和内存资源都被耦合刀了一台机器上,这样会导致计算和存储资源利用率低下(Resource efficiency ),并且整个架构的弹性(Elasticity)很差。
Disaggregated Memory
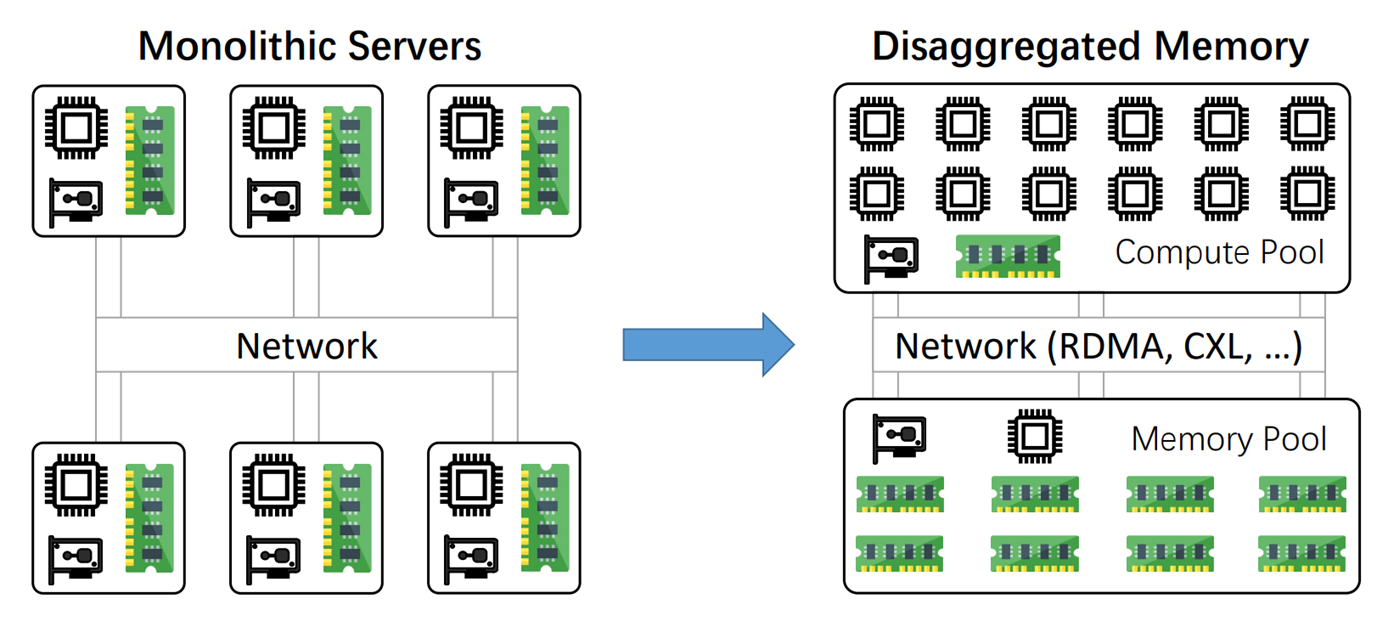
为了解决这个问题,后面的研究人员提出了一种解耦架构。具体来说,就是把原有在一台机器上的计算资源和存储资源分开并且集中,分为计算池和存储池。
计算池主要负责计算,拥有较强的计算能力和较弱的存储能力,存储能力主要服务于缓存,计算池在client端
存储池主要负责存储K-Vpair,拥有较弱的计算能力和较强的存储能力,计算能力主要服务于网络通信协议,存储池在Server端
两者通过一些新型的网络通信协议进行通信,使计算池能够直接对存储池进行操作。
这样的好处:
1.对于计算方面:计算资源能够统一调度共享。
2.对于存储方面:存储碎片化会减弱。
Existing Semi-Disaggregated Key-Value Stores
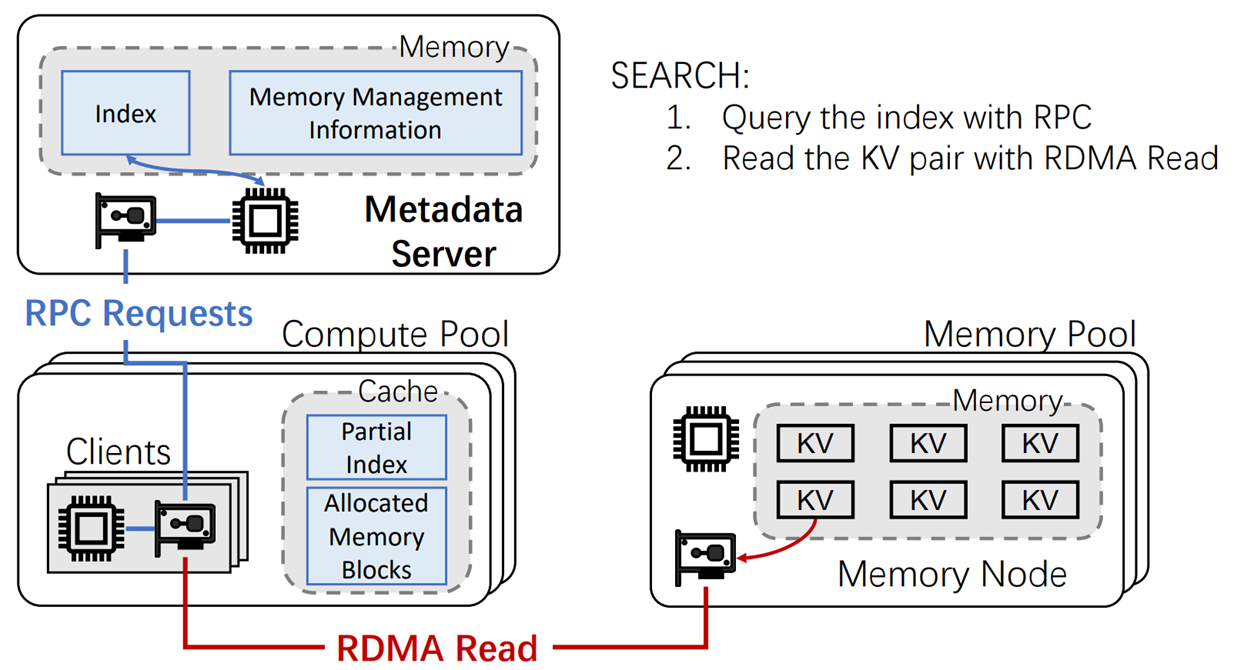
但是在K-V store中实现解耦架构使相对困难的,因为存储池的计算能力太弱,无法胜任元数据管理的工作。所以研究人员提出了一种半解耦架构,引入了一种单体服务器—元数据服务器(matadataServer)来单独完成对元数据进行管理任务,计算池依旧承担计算任务,存储池承担存储任务。
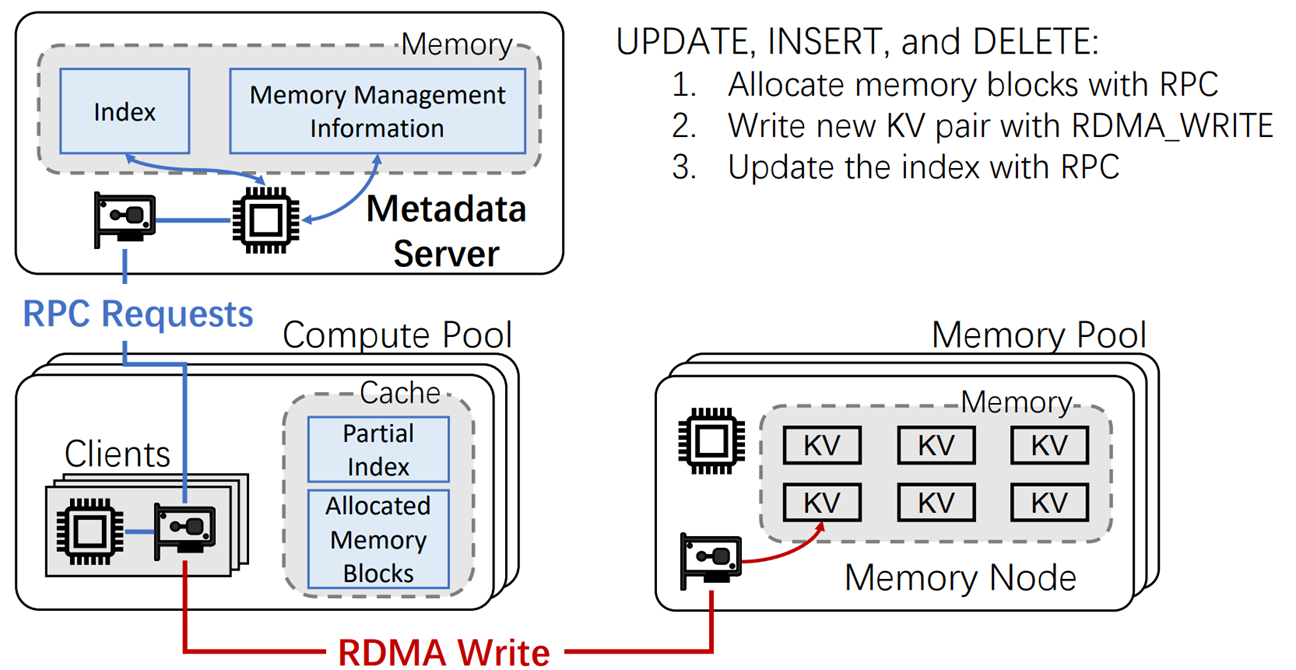
Serch操作
当进行Search操作时,主要有以下两步操作:
Step1:Client首先通过RPC对元数据服务器发起请求,获取所需要查询的K-V pair所在的Mermroy Node(后称MN)地址(元数据)。
Step2:获取到MN地址后,使用RDMA直接去对应的存储K-V pair的MN上直接进行K-V操作(Read),得到所需要的K-Vpair的信息
UPDATA INSERT DELETE操作
当进行UPDATA INSERT DELETE操作时,则需要多一步操作:
Step1:Client首先通过RPC对元数据服务器发起请求,获取所需要查询的K-V pair所在的MN的元数据
Step2:获取到MN地址后,使用RDMA直接去对应的存储K-V pair的MN上直接进行K-V操作(UPDATA INSERT DELETE),修改所需要的K-Vpair的信息
Step3:Clinet再向MatadataServer发起请求,将修改后的K-Vpair的元数据进行更新
Problem
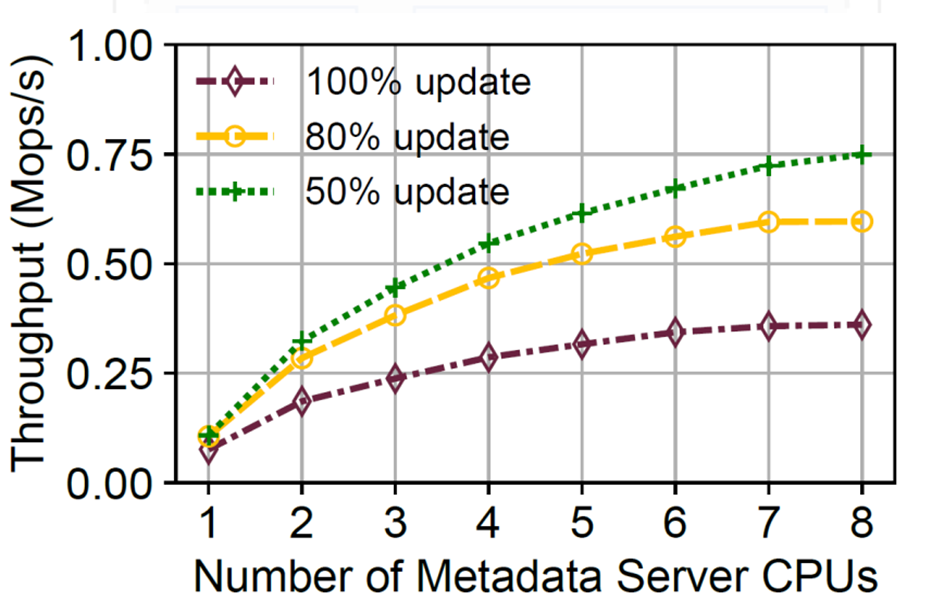
可以发现一个现象,就是所有的client在进行操作时,都需要访问元数据服务器,这对元数据服务器的性能存在很大的要求。这也是这篇paper主要想解决的问题:目前的半解耦模式因为元数据管理依旧依赖单体服务器,使的系统的性能没有被完全解放,依旧收到单体服务器(MatadataServer)限制。通过实验,元数据服务器至少要6个cpu核心,才能使其不成为资源调度瓶颈。
Motivation&Key Idea
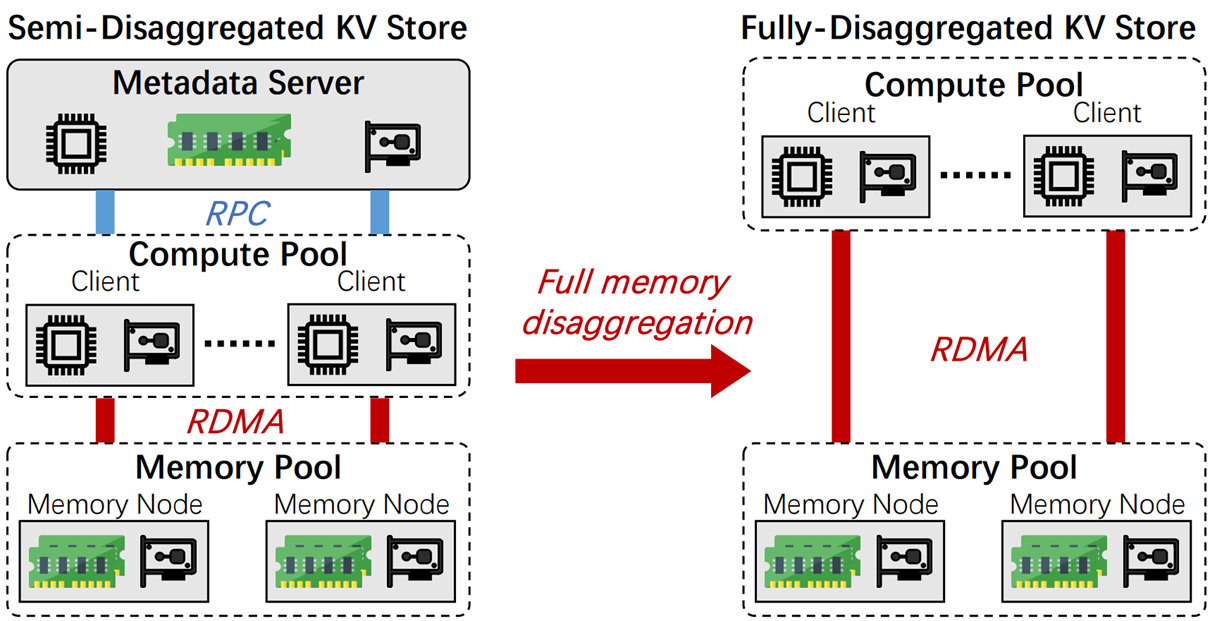
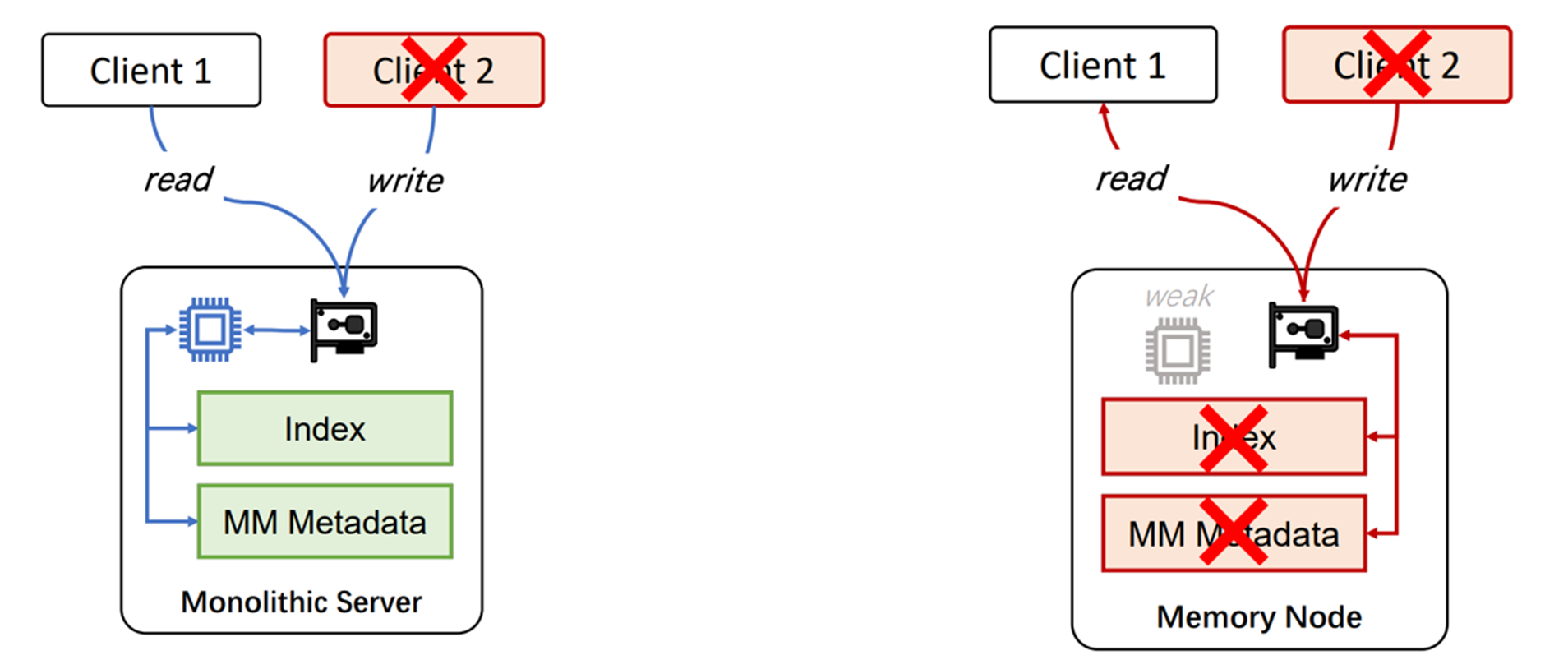
自然而然引出这篇paper的motivation:是否能够通过移除MatadataServer去实现一个完全解耦的架构。如下图所示的话,就是将架构从左边变为右边,移除了元数据服务器。
Key Idea:将元数据管理的任务交给计算池和存储池
Challenge
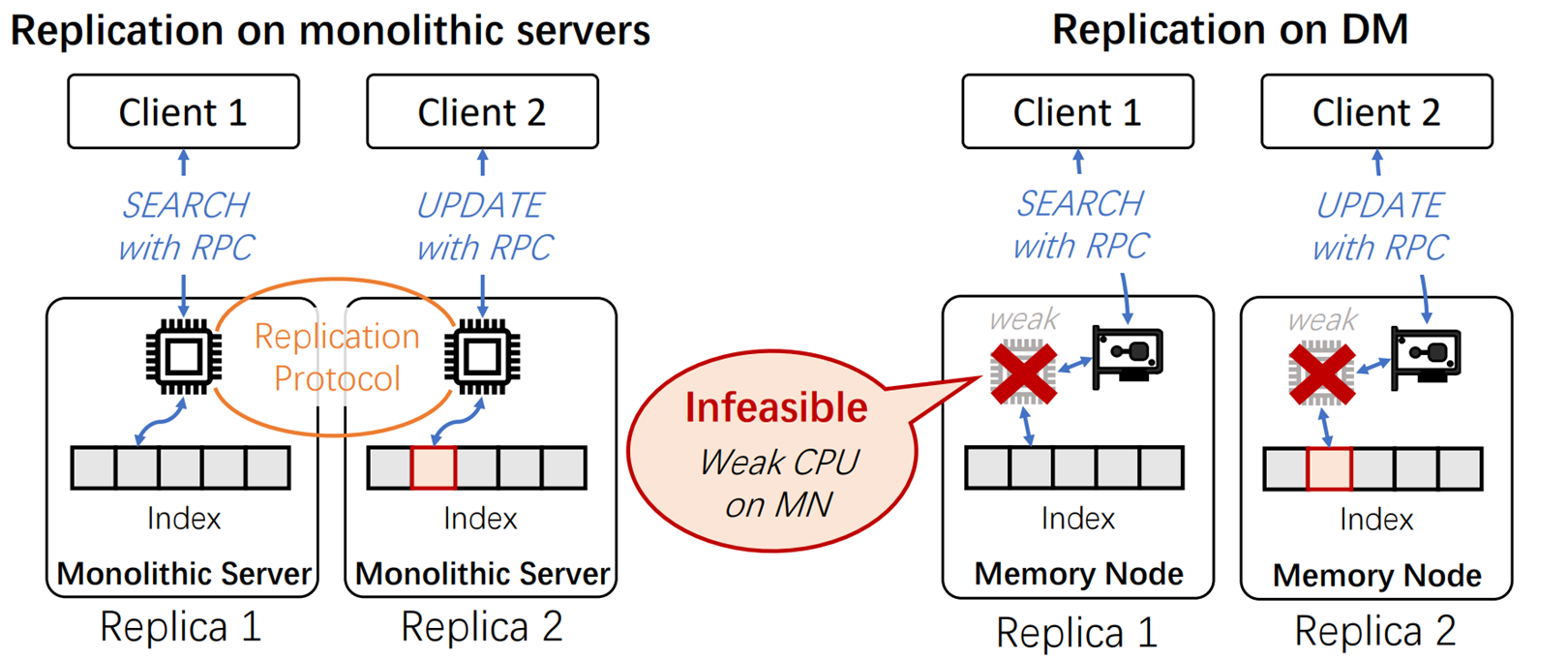
challeng 1:Client-Centric Index Replication
第一个挑战是以客户端为中心的索引赋值,在分布式系统中,需要把由不同客户端存储的index复制到其他server端(这是因为如果存在单一Server上,如果这个Server崩溃了,整个系统就G了),为了保证数据的一致性,目前的单体服务器之间是用过复制协议(Replocation Protocal)来完成的。
而这种方式在解耦架构的K-V store却无法使用,因为存储池的计算能力太弱了,无法运行复制协议。这样就无法保证数据的一致性。
challeng1总结:MN的计算能力太弱,无法运行复制协议,导致数据一致性无法保证
Challenge 2: Remote Memory Allocation
第二个挑战是远程内存分配,即如何进行比较好的内存管理计算。
在完全解耦模式下,有两种设想的可能性,第一种是以客户端为中心的方法,另一种是以服务器为中心的方法。
以客户端为中心的方法:是以存储节点来存储元数据,然后客户端通过远程操作协议直接计算,然后对元数据直接进行修改,但因为此时内存上是全部客户端的元数据,这样操作会造成很大的同步开销。
以服务端为中心的方法:指的是直接由存储阶段来对元数据进行计算管理,但因为元数据管理的计算量对于存储节点计算能力来说太大,所以很容因为client带来的请求,导致跟不上请求的速度。
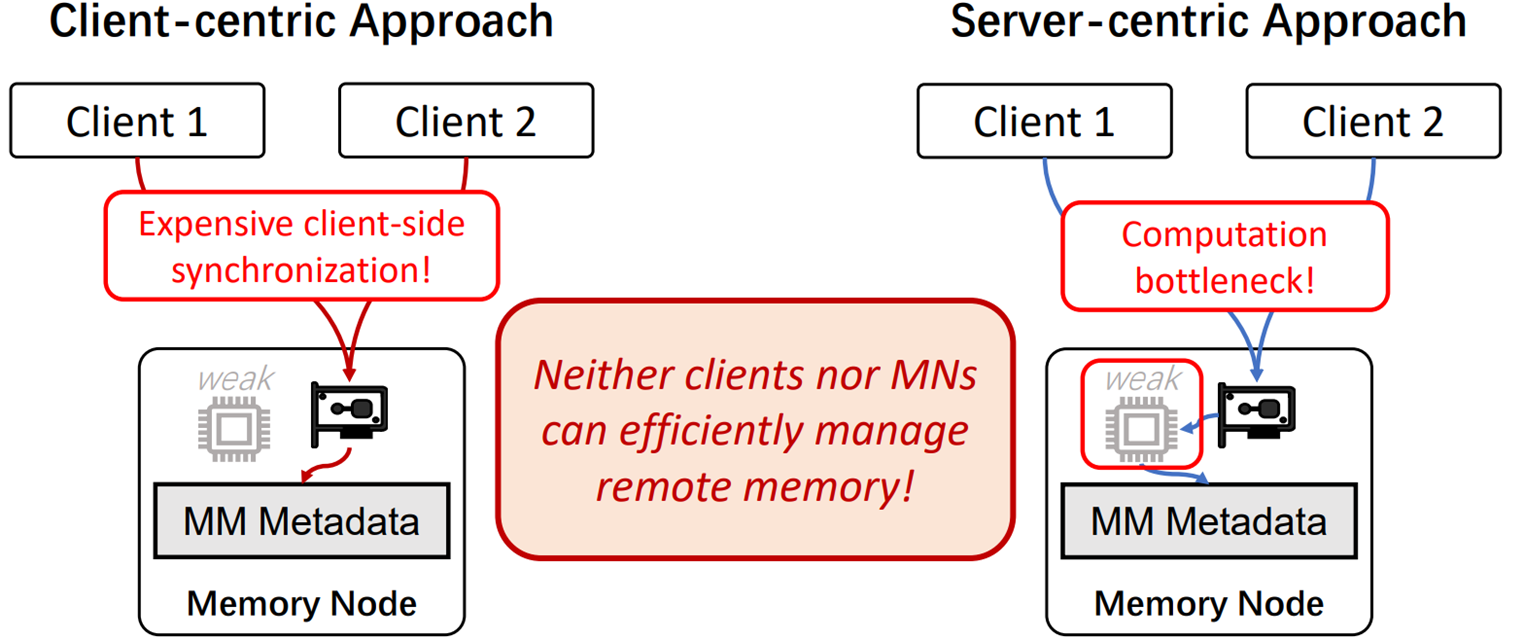
challenge2总结:MN的计算能力太弱,无法承担细粒度的内存管理任务
Challenge 3: Metadata Corruption
第三个挑战是,元数据损坏问题
因为在整个分布式环境中,节点之间是非常不稳定的,客户端随时都有崩溃的风险。在传统的单体服务器架构中,如果其中一个Client崩溃了,由于存在元数据服务器或者单体服务器本身CPU的管理,不会对元数据进行污染。其他正常Client读到也是正常数据。
但是如果是在完全解耦的场景下,Client崩溃会导致部分元数据的修改已经整合到内存节点的元数据中,会导致其他正常的Client读到错误的数据。例如,当一个Client在对一个K-V pair进行UPDATE操作中途崩溃了,此时别的Client2读取的就是错误的K-V pair
Challenge3总结:完全解构架构下,Client崩溃会影响到整个系统
FUSEE Overview
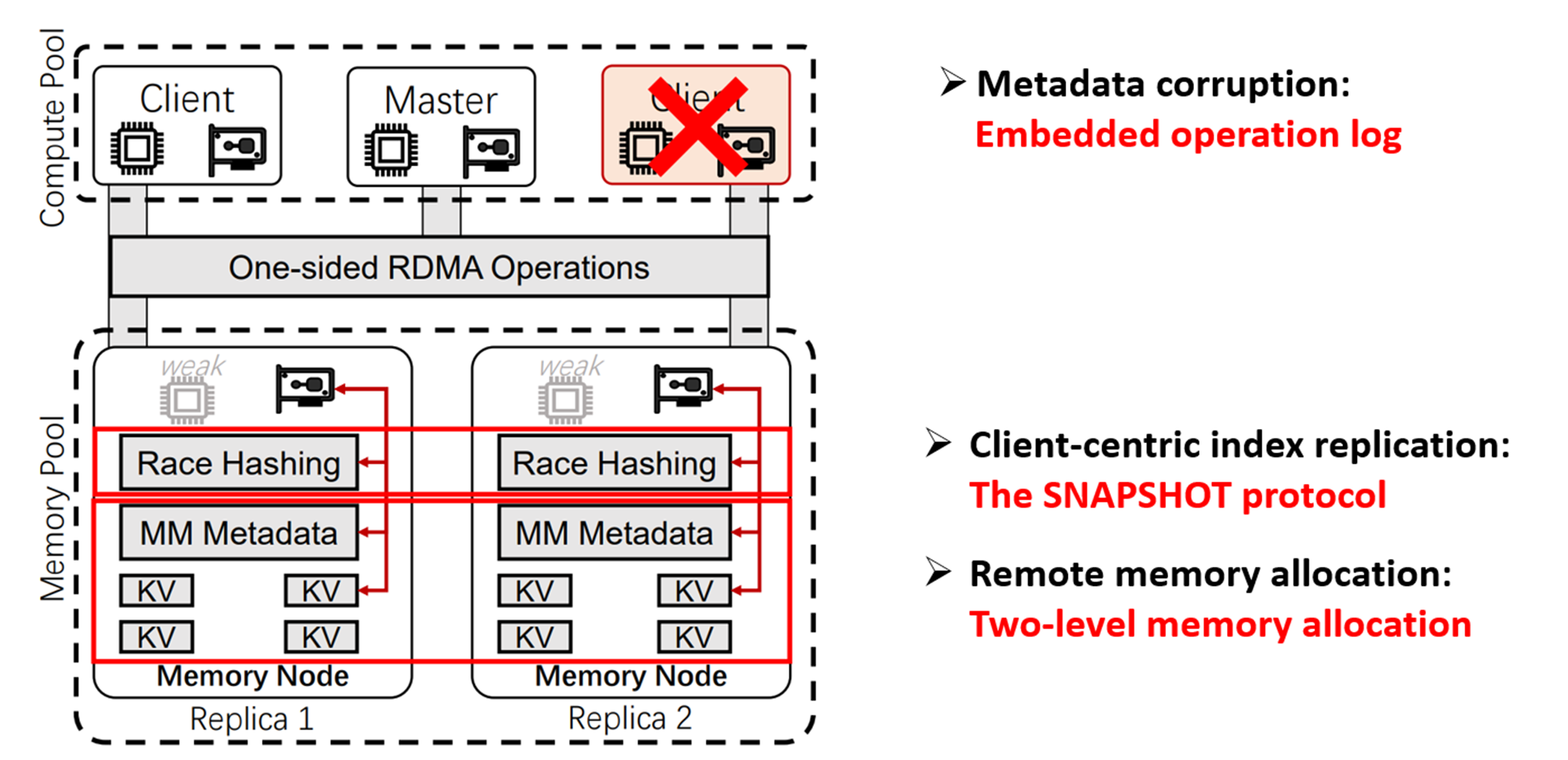
接下来我们看一下FUSEE的Overview,可以看到整个FUSEE架构还是又2计算池和存储池两大部分组成,其中这个Master负责初始化工作,不参与其他工作
FUSEE提出了三个设计
第一个是快照协议解决服务端中心index复制问题
第二个是两级内存管理机制,解决远程内存管理问题
第三个是嵌入式操作日志,解决元数据损坏问题
Design
Design1:The SNAPSHOT protocol
首先是第一个设计,快照协议.回到我们的第一个挑战,因为在内存结点中无法进行通过复制协议保证数据一致性。比如这个图,可能不同的客户端可能对不同节点同时进行读写操作。
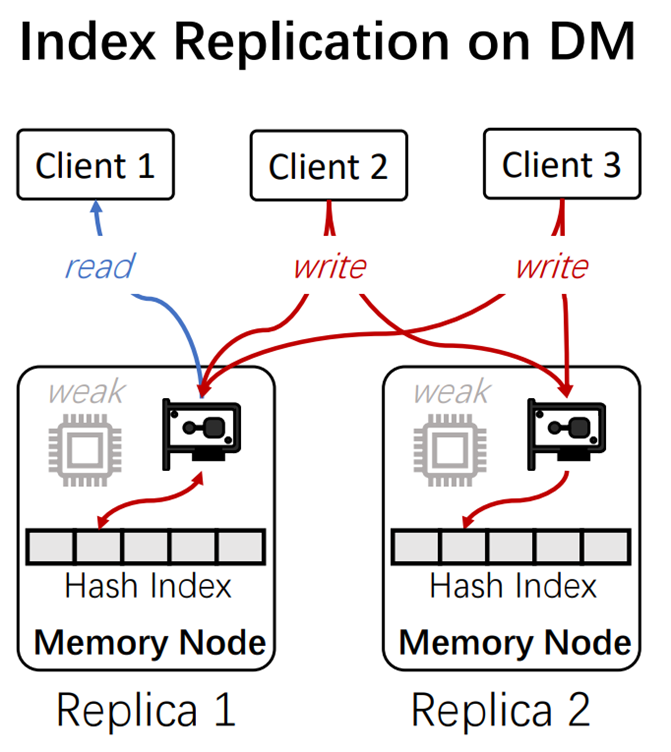
而保证数据一致性主要有以下两个关键问题:
第一个是如何保证读用户不能够读到不完整的数据(Read)
第二个是如何有效的保证写用户之间造成的冲突(Write)
Key-problem 1:Read
针对第一个关键问题,为了防止单一节点崩溃导致不可用,Memery pool将索引分成了一个主要副本(Primary Slot)和多个备份副本(Backup Slot),读用户永远只读主副本的元数据作为结果,因为主副本有且仅有一份,保证所有读用户读到的都是一样的数据。
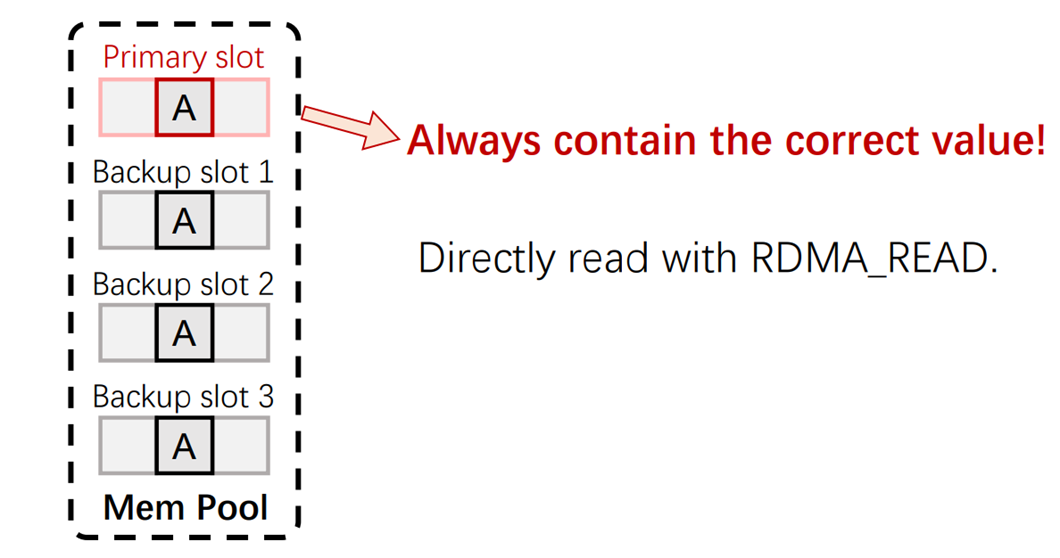
Key-problem 2:Write
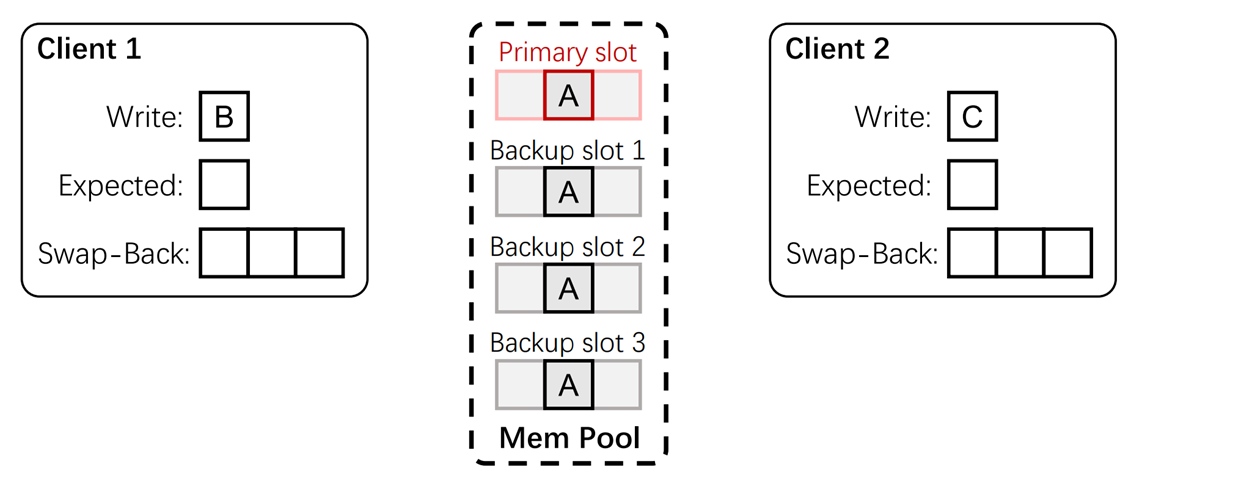
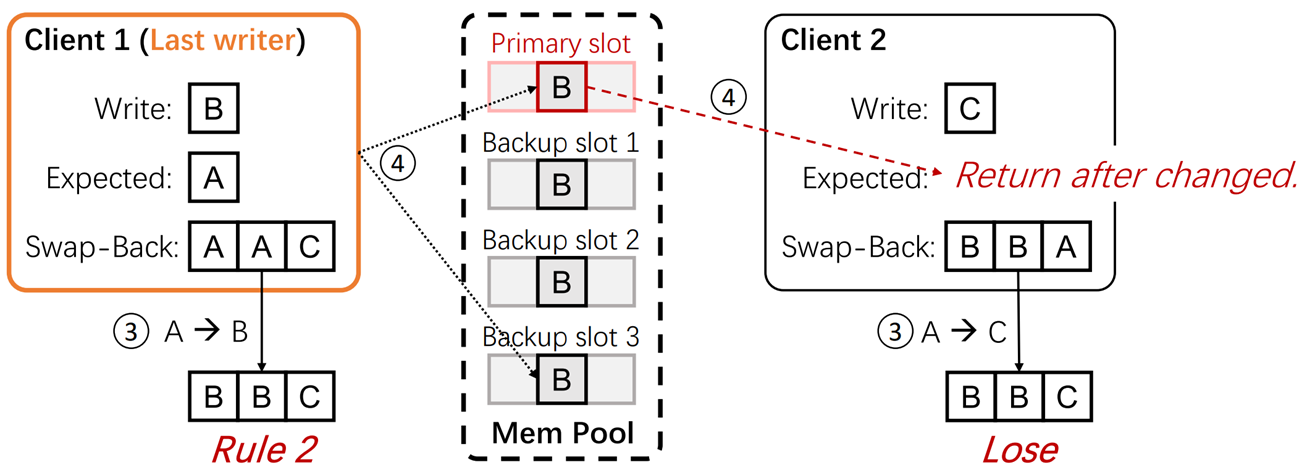
正对第二个关键问题,即不同用户同时写入不同的值,本文提出了最后写者胜(last-writer-wins)的方法,怎么去理解这个方法呢,看这个图,Memery pool已经完成了复制,有主要副本和多个备份副本。此时有两个Client相对A这个K-V pair进行修改,Client1想修改为B,Client2想修改为C。
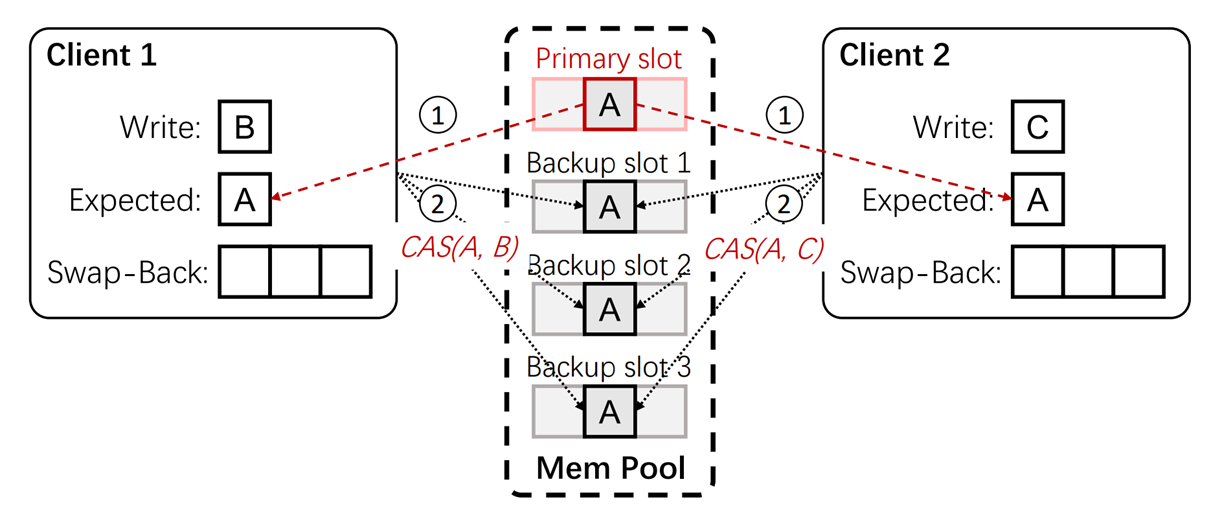
第一步,两个Client都会与主要副本进行通信,获取期望值(Expected):A,然后对所有的备份副本进行通信,若此时备份副本插槽值和期望值(Expected):A相同,说明这个备份副本未被修改,进行抢夺修改,若和A不同,则说明此时这个备份副本已被别的Client修改,就通信下一个备份副本。(相当于就是两个Client抢备份副本)
第二步,当两个Client通信完所有备份副本后,比较备份副本插槽的序列
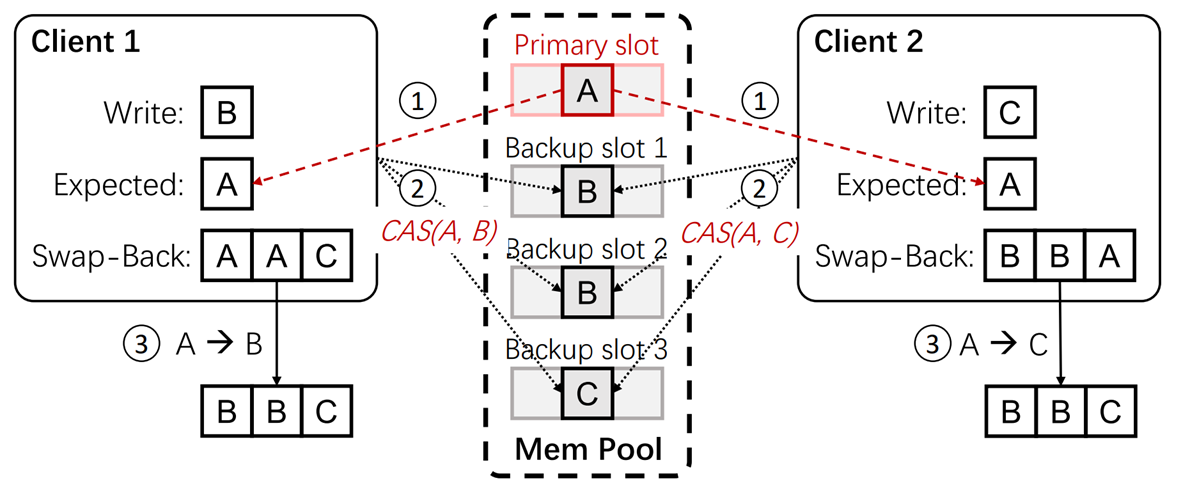
第三步,使用以下规则确定最后的胜者
1.成功修改完所有的备份副本的Client为胜者
2.成果修改完大部分的备份副本的Client为胜者
3.若没有修改完大部分的备份副本的Client,则值最小的Client为胜者
以这个例子为例,备份副本插槽的序列为BBC,Client1为修改完大部分的备份副本的Client,成为胜者,将主要副本的插槽修改为B。
Design2:Two-Level Memory Management
这个设计的key idea 是将整个元数据管理计算任务拆分成简单计算任务和复杂计算任务两部分
当有一个请求过来时,将2GB空间分成块,内存结点将块分给Client,再有Client细致对这块内存进行管理。
具体来说:当Client A发起需要内存管理的请求(INSERT)时,MN首先选择一块数据块Block A,Block的大小一般为4KB、8KB、16KB,将其分配给发起请求的Client A,并添加一个index (Block A,Client A),明确Block A由Client A管理。然后Client A对Block A进行操作,在里面选择最适宜大小的位置,插入K-v pair。然后管理Block A里面的元数据。
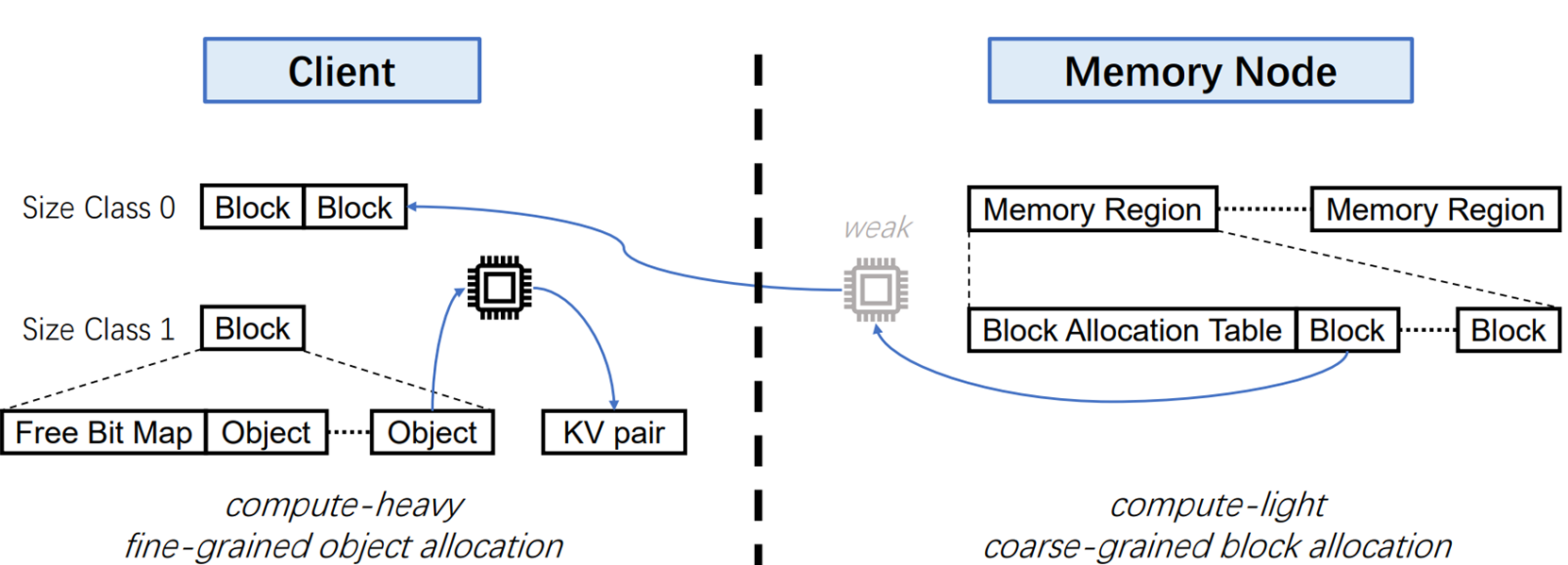
这样MN承担管理大块的工作(计算量小),Clent承担小块的具体内存管理的工作(计算量小),此方法的同步开销也比较低,因为各Clent管理的不是全局的内存,而是分配给他的小块内存。
Design 3:Embedded Operation Log
这个设计的Key idea是:将日志信息嵌入到K-v pair中,减少传输开销。
元数据恢复一般通过日志来完成的,每完成一个操作,就在日志信息里面加一条。
日志序列必须和K-V pair的操作序列一致,所以单独发送日志信息,会需要额外的开销。
本文的主要思路是将日志和K-Vdata 一起打包传送,分配前就使用指针将logEntry按顺序串联起来(是一个双双向链表的数据结构),然后因为K-V pair是按顺序进行分配的,所以logEntry也具有了序列化。
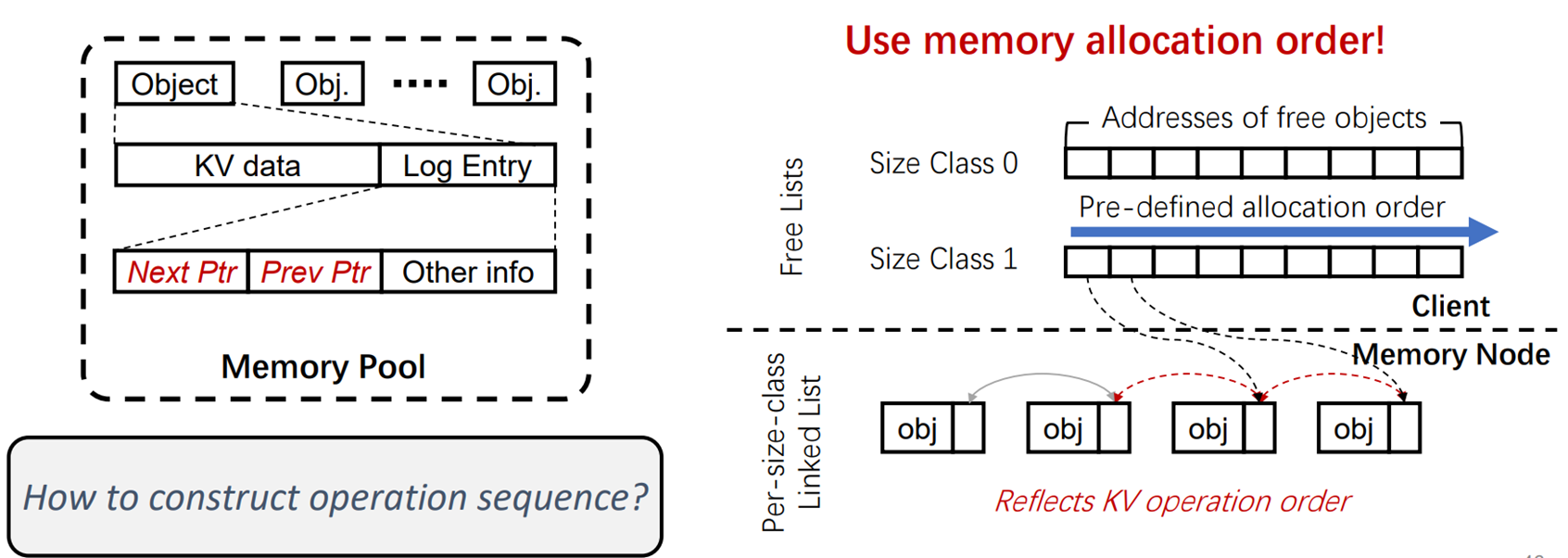
ps:这部分理解的不是很懂,大家可以看看原文,了解细节。。。TAT
Evaluation(只给了重点实验哈,更多请见paper)
Platform
数据集分为两类:
第一类YSCB:就是混合数据集,各个操作(SEARCH UPDATA INSERT DELETE操作)的占比不同,其中
YSCB-A为写密集数据集
YSCB-C为读密集数据集
第二类Microbenchmark :单一操作数据集,EARCH UPDATA INSERT DELETE
对照方法:
1.Clover:最新的半解耦K-V store架构,就是有元数据服务器哒(见background)
2.pDPM-Direct:以客户端为中心的远程内存管理,具有很大同步开销哒(见Challenge)
Latency&Throughput
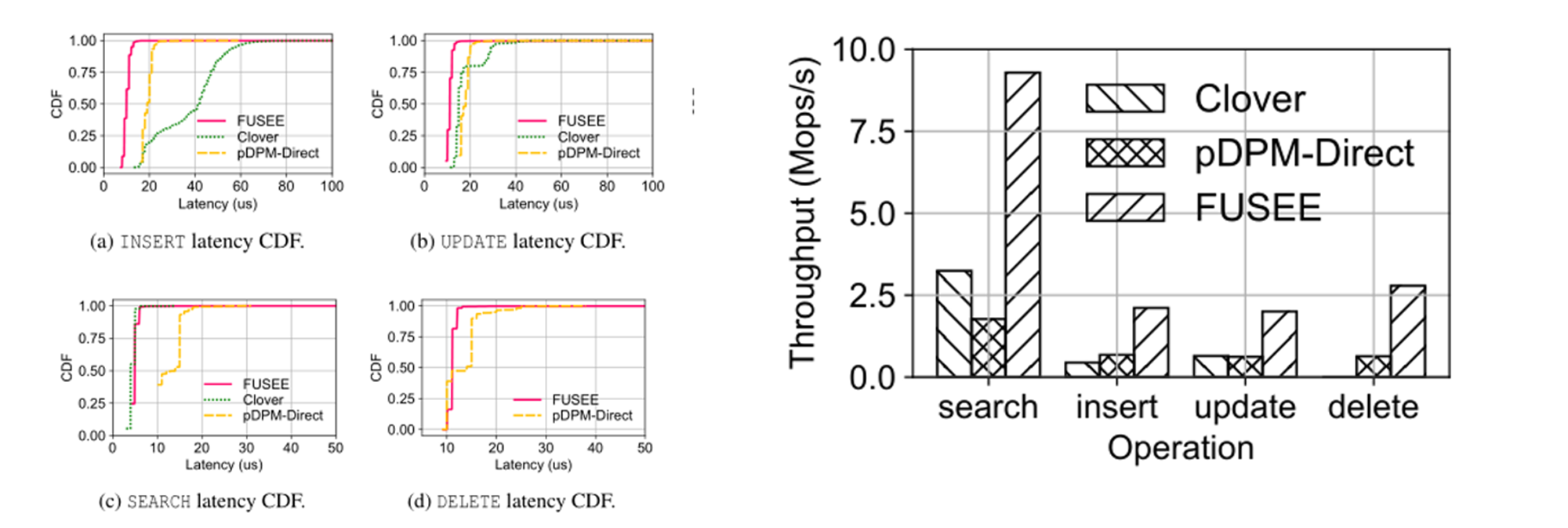
**Latency:**FUSE在INSERT和UPDATE上的表现最好,因为SNAPSHOT复制协议有限制的RTT。FUSE的SEARCH延迟略高于Clover,因为FUSE在单个RTT中读取哈希索引和KV对,这比仅在Clover中读取KV对慢。FUSE的DELETE延迟略高于pDPM Direct,因为FUSE在单个RTT中写入日志条目并读取哈希索引,这比仅在pDPM Direct中读取哈希索引要慢。
**Throughput:**pDPM Direct的吞吐量受到其远程锁的限制,随着客户端数量的增长,远程锁会导致大量的锁争用。对于Clover来说,尽管它消耗了更多的硬件资源,即8个额外的CPU内核和一个RNIC,但可扩展性仍然低于FUSE。这是因为元数据服务器的CPU处理能力限制了其吞吐量。相反,FUSE通过消除元数据服务器的计算瓶颈并有效解决与SNAPSHOT复制协议的冲突,提高了整体吞吐量。
主要是体现设计的总体效果。
YCSB-Throughput & Two-level memory allocation performance

**YCSB-Throughput:**当使用128个客户端将MN的数量从2个改变到5个时,具有写密集型工作负载(YCSB-a)和读密集型工作负荷(YCSB-C)的三种方法的吞吐量。pDPM Direct和Clover的吞吐量并没有增加,因为它们分别受到锁争用和元数据服务器有限计算能力的限制。对于FUSE,吞吐量随着内存节点数量从2个增加到3个而提高。由于总吞吐量受到计算节点数量的限制,因此没有进一步的吞吐量改进。
**Two-level memory allocation performance:**为了显示两级内存分配方案的有效性,我们将FUSE与以MN为中心的内存分配方案进行了比较,如图所示。由于MN上的计算能力有限,YCSB-A吞吐量下降了90.9%,而YCSB-C吞吐量保持不变,因为只读设置中不涉及内存分配。
主要是体现第二个设计的作用
Recover from Crashed Clients
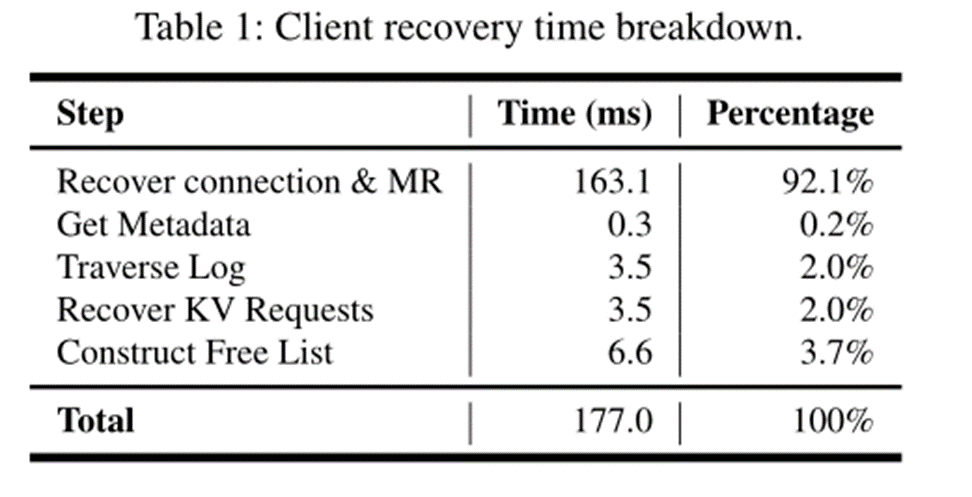
**Recover from Crashed Clients:**为了评估客户端从故障中恢复的效率,在更新1000次后崩溃并恢复客户端。FUSE从客户端故障中恢复需要177毫秒。内存注册和连接重新建立占总恢复时间的92%。日志遍历和KV请求恢复只占恢复时间的4%,这意味着日志遍历的开销是可以承受的。(第三个设计总体不是很明白orz)
Conclusion
最后是一个我自己对这篇paper的总结,我感觉这篇paper还是蛮interesting的